
呼市365手机app_彩票365app老版本软件下载_365网站打不开了 优化揭秘搜索引擎原理
发布时间 :2011/03/25
所谓“搜索引擎”,说到底是一个计算机应用软件系统,或者说是一个网络应用软件系统。它大致上被分成三个功能模块,或者三个子系统;即网页搜集,预处理和查询服务。在实践中这三个部分是相对独立的,它们的工作形成了搜索引擎工作的三个阶段。
能够接受用户通过浏览器提交的查询词或者短语,记作q,例如“人流”,“分妇科检查”,“人流多少钱”等等。
在一个可以接受的时间内返回一个和该用户查询匹配的网页信息列表,记作L。这个列表的每一条目少包含三个元素(标题,网址链接,摘要)。 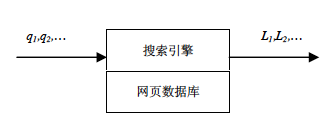
图1,搜索引擎示意图
有分析统计表明,用户平均察看返回结果不超过2页。现代大规模高质量搜索引擎一般采用如图2所示的三段式的工作流程,即:网页搜集、预处理和查询服务。
搜索引擎三段式工作流程
阶段:网页搜集(网页搜集子系统)
一般是增量搜集,开始时搜集一批,往后只是(1)搜集新出现的网页,(2)搜集那些在上次搜集后有过改变的网页,(3)发现自从上次搜集后已经不再存在了的网页,并从库中删除。(有研究指出50%网页的平均生周期大约为50天).
在具体搜集过程中,常见的一种是所谓“爬取”:将Web上的网页集合看成是一个有向图,搜集过程从给定起始URL集合S(或者说“种子”)开始,沿着网页中的链接,按照先深、先宽、或者某种别的策略遍历,不停的从S中移除URL,下载相应的网页,解析出网页中的超链接URL,看是否已经被访问过,将未访问过的那些URL加入集合S。整个过程可以形象地想象为一个蜘蛛(spider)在蜘蛛网(Web)上爬行(crawl)。 真正的系统其实是多个“蜘蛛”同时在爬。
“蜘蛛”(spider)。 在文献中crawler, spider, robot一般都指的是相同的事物,即在Web上依照网页之间的超链关系一个个抓取网页的程序,通常也称为“搜集”。在搜索引擎系统中,也称为网页搜集子系统。
第二阶段:预处理(预处理子系统)
“倒排文件”(inverted file);倒排文件是用文档中所含关键词作为索引,文档作为索引目标的一种结构(类似于普通书籍中,索引是关键词,书的页面是索引目标)
下面讨论从网页集合形成这样的倒排文件过程中的几个主要问题,即我们所说的“预处理”。主要包括四个方面,关键词的提取,“镜像网页”(网页的内容相同,未加修改)或“转载网页”(near-replicas,主题内容基本相同但可能有一些额外的编辑信息等,转载网页也称为“近似镜像网页”)的,链接分析和网页重要程度的计算。
1.关键词的提取
据统计,网页文档源文件的大小(字节量)通常大约是其中内容大小的4倍.由于HTML文档产生来源的多样性,许多网页在内容上比较随意,不仅文字不讲究规范、完整,而且还可能包含许多和主要内容无关的信息(例如广告,导航条,版权说明等)。
为了支持后面的查询服务,需要从网页源文件中提取出能够代表它的内容的一些特征。 所含的关键词即为这种特征好的代表。于是,作为预处理阶段的一个基本任务,就是要提取出网页源文件的内容部分所含的关键词。对于中文来说,就是要根据一个词典Σ,用一个所谓“切词软件”,从网页文字中切出Σ所含的词语来。在那之后,一篇网页主要就由一组词来近似代表了,p = {t1, t2, …, tn}。一般来讲,我们可能得到很多词,同一个词可能在一篇网页中多次出现。从(effectiveness)和效率(efficiency)考虑,不应该让所有的词都出现在网页的表示中,要去掉诸如“的”,“在”等没有内容指示意义的词,称为“停用词”。这样,对一篇网页来说,有效的词语数量大约在200个左右。
2. 重复或转载网页的
Web上的信息存在大量的重复现象。它不仅在搜集网页时要消耗机器时间和网络带宽资源,而且如果在查询结果中出现,无意义地消耗了计算机显示屏资源,也会引来用户的抱怨,“这么多重复的,给我一个就够了”。因此,内容重复或主题内容重复的网页是预处理阶段的一个重要任务。
3. 链接分析
从信息检索的角度讲,如果系统面对的仅仅是内容的文字,我们能依据的就是“共有词汇假设”(shared bag of words),即内容所包含的关键词集合,多加上词频(term frequency 或tf、TF)和词在文档集合中出现的文档频率(document frequency 或df、DF)之类的统计量。而TF和DF这样的频率信息能在一定程度上指示词语在一篇文档中的相对重要性或者和某些内容的相关性,这是有意义的。有了HTML标记后,情况还可能进一步改善,例如在同一篇文档中,
和
之间的信息很可能就比在和
之间的信息更重要。特别地,HTML文档中所含的指向其他文档的链接信息,认为它们不仅给出了网页之间的关系,而且还对判断网页的内容有很重要的作用。4. 网页重要程度的计算
由于面对各种各样的用户,加之查询的自然语言风格,对同样的q0返回相同的列表肯定是不能使所有提交q0的用户都满意的(或者都达到高的满意度)。因此搜索引擎实际上追求的是一种统计意义上的满意。这里只是概要解释在预处理阶段可能形成的所谓“重要性”因素。顾名思义,既然是在预处理阶段形成的,就是和用户查询无关的。如何讲一篇网页比另外一篇网页重要?人们参照科技文献重要性的评估方式,核心想法就是“被引用多的就是重要的”。“引用”这个概念恰好可以通过HTML超链在网页之间体现得好,作为Google创立核心技术的PageRank就是这种思路的成功体现。这些指标有的可以在预处理阶段计算,有的则要在查询阶段计算,但都是作为在查询服务阶段终形成结果排序的部分参数。
第三阶段 查询服务(查询服务子系统)
从一个原始网页集合S开始,预处理过程得到的是对S的一个子集的元素的某种内部表示,这种表示构成了查询服务的直接基础。对每个元素来说,这种表示少包含如下几个方面:
a. 原始网页文档
b. URL和标题
c. 编号
d. 所含的重要关键词的集合(以及它们在文档中出现的位置信息)
e. 其他一些指标(例如重要程度,分类代码等)
而系统关键词总体的集合和文档的编号一起构成了一个倒排文件结构,使得一旦得到一个关键词输入,系统能迅速给出相关文档编号的集合输出。用户通过搜索引擎看到的不是一个“集合”,而是一个“列表”。如何从集合生成一个列表,是服务子系统的主要工作。下面来看对服务子系统的要求和其工作原理,主要有三个方面:
1.查询方式和匹配
查询方式指的是系统允许用户提交查询的形式。一般来讲,系统面对的是查询短语。就英文来说,它是一个词的序列;就中文来说,它是包含若干个词的一段文字。一般地,我们用q0表示用户提交的原始查询,例如,q0 =“玛丽与妇婴哪个好”。它先需要被“切词”(segment)或称“分词”,即把它分成一个词的序列。如上例,则为“玛丽 与 妇婴 哪个 好”。然后需要删除那些没有查询意义或者几乎在每篇文档中都会出现的词(例如“的”),在本例中即为“与”。后形成一个用于参加匹配的查询词表,q = {t1, t2, …, tm},在本例中就是q = {玛丽,妇婴,哪个,好}。前面讲过,倒排文件就是用关键词来作为索引的一个数据结构,显然,q中的词必须是包含在倒排文件词表中才有意义。有了这样的q,它的每一个元素都对应倒排文件中的一个倒排表(文档编号的集合),记作L(ti),它们的交集即为对应查询的结果文档集合,从而实现了查询和文档的匹配。
2. 结果排序
上面,我们了解了得到和用户查询相关的文档集合的过程。这个集合的元素需要以一定的形式通过计算机显示屏呈现给用户。列表是常见的形式 。给定一个查询结果集合,R={r1, r2, …, rn},所谓列表,就是按照某种评价方式,确定出R中元素的一个顺序,让这些元素以这种顺序呈现出来。笼统地讲,ri和q的相关性(relevance)是形成这种顺序的基本因素。当我们通过前述关键词的提取过程,形成一篇文档的关键词集合,p = {t1, t2, …, tn}的时候,很容易同时得到每一个ti在该文档中出现的次数,即词频,而倒排文件中每个倒排表的长度则对应着一个词所涉及的文档的篇数,即文档频率。通过在预处理阶段为每篇网页形成一个独立于查询词(也就和网页内容无关)的重要性指标,将它和查询过程中形成的相关性指标结合形成一个终的排序,是搜索引擎给出查询结果排序的主要方法。简单点说就是: 提取出各网页的关键词和文档编号,原始是按网页编号排列成集合,然后转置为按关键词为主键排序成新的集合。
3. 文档摘要
搜索引擎给出的结果是一个有序的条目列表,每一个条目有三个基本的元素:标题,网址和摘要。
标题:以某种方式得到的网页内容的标题。简单的方式就是从网页的
URL:该网页对应的“访问地址”。有经验的Web用户常常可以通过这个元素对网页内容的权威性进行判断,例如http://www.*****.com上面的内容通常就比http://*****.net上的要更权威些(不排除后者上的内容更有趣些)。
摘要:以某种方式得到的网页内容的摘要。简单的一种方式就是将网页内容的头若干字节截取下来作为摘要。
搜索引擎在生成摘要基本上可以归纳为两种方式,一是静态方式,即独立于查询,按照某种规则,事先在预处理阶段从网页内容提取出一些文字,例如截取网页正文的开头512个字节(对应256个汉字),或者将每一个段落的个句子拼起来,等等。
二是“动态摘要”方式,即在响应查询的时候,根据查询词在文档中的位置,提取出周围的文字来,在显示时将查询词标亮。这是目前大多数搜索引擎采用的方式。
四,“控制器”模块。
“控制器”的作用,核心是要综合解决效率、质量和“礼貌”的问题。
所谓效率问题,在这里就是如何利用尽量少的资源(计算机设备、网络带宽、时间)来完成预定的网页搜集量。
所谓“礼貌”问题,是指比如将搜集活动的关注过分集中在几个365手机app_彩票365app老版本软件下载_365网站打不开了 上,或者在一小段时间里从一个365手机app_彩票365app老版本软件下载_365网站打不开了 抓取太多的网页还可能引起其他的严重后果,造成365手机app_彩票365app老版本软件下载_365网站打不开了 变慢甚崩溃等。
所谓质量问题,指的是在有限的时间,搜集有限的网页,希望它们尽量是比较“重要”的网页,或者说不要漏掉那些很重要的网页。
网页搜集过程中还有一个基本的问题是要保证每个网页不被重复抓取。由于一篇网页可能被多篇网页链接,在spider爬取过程中就可能多次得到该网页的url。于是如果不加检查和控制,网页就会被多次抓取。遇到循环链接的情况,还会使爬取器陷死。解决这个问题的有效方法是使用两个表,unvisited_table和visited_table。前者包含尚未访问的url,后者记录已访问的url。系统先将要搜集的种子url放入unvisited_table,然后 spider从其中获取要搜集网页的url,搜集过的网页url放入visited_table中,新解析出的并且不在visited_table中的url加入unvisited_table。 这样一来,我们就大致形成里搜索引擎的体系结构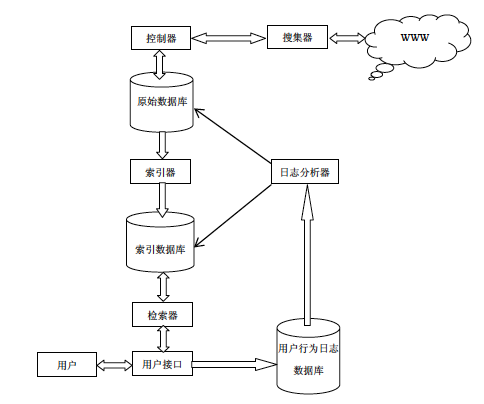
搜索引擎的体系结构